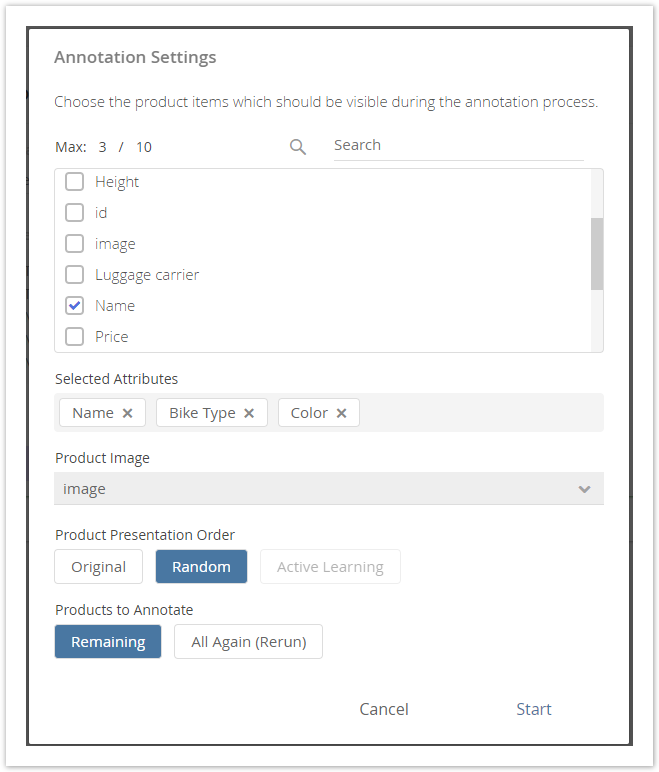
The annotation settings modal window becomes visible if is shown every time a new annotation process is started by clicking the "Start Annotation" button in the Annotation view is clicked. It look like the example . Settings from the previous session are stored and preselected the next time the process is started. An example of such settings modal window is depicted in the image below.
Structure
...
Within the attribute selection you can decide which information from your products should be visible during the annotation process. For example, if you select the attribute Color, the color information is displayed for each product. This information should help you to decide which attribute value annotation is the best fit for a most suitable for each product.
You can use the search bar to easily find an attribute. All selected attributes are displayed below the checkbox list as tags (max. selection is 10). They can be removed via the "x" icon in the tags or by deselecting the attribute in the checkbox list.
...
Like in the attribute selection above, you have to choose an attribute out of your data feed. In contrast, the information of this attribute is not displayed as text information but rendered as an image. That means that the image URL is converted into an image. With the aid of that image, it is easier to identify the product or decide which attribute values needs need to be annotated.
| Info | ||
|---|---|---|
| ||
If you have mapped the core attribute image during the data feed import (see Set the Attribute Mapping) the image selection is automatically preselected with this attribute. |
...
- Original:
See all products in the order of your data feed. That means that the first product of your data file will be the first product to annotate and so on. - Random:
The product sequence you will see during the annotation process is completely random. That means that it is unpredictable which product will be presented next. Active Learning:
will be adapted depending on the annotated products. The annotation process will present products where the prediction model is uncertain about the fitting attribute value
The product sequence isdetermined by the prediction model, prioritising more informative products to be labeled first. The model will try to select products for which it is most uncertain what the correct attribute value is or which are most dissimilar from the already annotated ones with respect to the training attributes.
Note title Caution This strategy is only appropriate when the selected training attributes are informative enough to determine the correct attribute value and when the model is already performing decently. If, in contrary, the model is performing very poorly, it might introduce sampling bias and require even more products to be annotated in this manner as opposed to applying the other strategies to achieve a similar model improvement.
As a rule of thumb, you might want to achieve at least 70% accuracy before using this strategy to reduce the annotation effort required to take your model to the next level.
| Advantages | Disadvantages | |||
|---|---|---|---|---|
| Original |
|
| ||
| Random |
| Random |
|
|
| Active Learning |
|
|
Annotation Mode
Lastly, you have to decide which products you want to annotate. This step is only relevant if you already have product annotations. The two decisions are:
...